

Machine learning-powered drug discovery: Now and Tomorrow
Part II. Platform, business model, scaling, and emerging trends

II
What are AI-first companies?
According to Ash Fontana, author of ‘The AI-First Company’, they are companies that build competitive advantages through AI. They start collecting meaningful data from day one and constantly acquire new data to improve predictive models to automate the core functions. Google is the original AI-first company. It built out a search engine using methods from AI. As the company grew, it strategically gave away certain products for free to collect data from the users, which were further used to improve its core learning loop.
In the drug discovery industry, AI-first companies are built around AI/ML models that predict disease targets, drug properties, treatment responses, etc. They typically have the in-house infrastructure and expertise to generate large-scale biodata to train and validate their models. They are essentially bio and tech companies at the same time.
Disclaimer: Sometimes, people use the term AI and ML interchangeably. There have been few AI tools besides ML used in drug discovery. To be more accurate, I will stick to ‘ML’ in this post. However, I will use the term ‘AI-first or AI-native companies’ as it has been used and accepted widely.
Features of AI-first biotech companies
The first generation of AI-first biotech companies started to emerge around 2012. So far, there are over 200 companies in this space. I took a closer look into 40+ AI-first companies that developed ML-based platforms directly contributing to discovering new drug candidates or repurposing existing drugs. As these companies matured, patterns started to emerge. They showed some defining characteristics that are fundamentally different from typical asset-centric biotech companies:
Platform-first company structure
Versatile business models
Scaling up like tech companies
Let’s talk about these features in detail.
Platform-first company structure
Choosing between a platform-first or asset-first structure is like a choice between the goose or the golden egg. Therapeutic assets are like the golden egg of the biotech industry; if successful, they can bring enormous value to the company. Platforms are like the goose; theoretically, any biotech company can claim that they have a platform, but not all platforms are productive. A decision that most biotech companies have to face is whether they should spend their limited resources on feeding the goose, which may or may not produce a golden egg, or if they should invest in a few therapeutic assets that are the golden egg.
However, ML platforms are different; they are designed to transform artisanal drug-making into industrialized drug development. The value of an ML platform is attributed to its ‘KPI’, the number of successful drug targets or candidates the platform can generate. Therefore, instead of the ‘platform vs asset’ decision, the fundamental question for AI-first biotech companies is how to build a platform that delivers 10x or even 100x efficiency.
Any AI-first biotech companies who are serious about using ML for drug discovery are enabled by platforms that are composed of high-quality, ML-grade data, wet lab infrastructure, and computing resources.
High-quality, ML-grade data
A unique, rich dataset is the secret sauce for successful AI-first companies. In a simplified fashion, three types of data have been used to train ML models in drug discovery. 1). Compound library and characterization data, which consists of information on drug compounds such as structure, affinity, solubility, stability, etc. 2). Molecular profiling data, which refers to omics data of biomolecules (DNA, RNA, proteins, methylation, etc) in a whole organism. 3). Phenotyping data, including parameters related to cell morphology, organelle dynamics, animal behaviors, and patients’ clinical data.
There is a rich body of data from public databases. For example, PDB contains 3D structural information of over 160 000 large biological molecules. DrugBank is a public knowledge database and API for over 500 000 drugs and drug products. These databases are widely used for building ML models for drug discovery. However, public datasets bear big variations in data quality and coverage, and sometimes are unstructured. Often, data scientists have to do extensive data engineering to ensure the public datasets meet the ML standard. As a result, more companies seek to generate high-quality, proprietary datasets in-house, which not only grants them better control over the data quality but also guarantees their full ownership of IPs generated from such datasets.
Wet lab infrastructure
The major difference between artisanal drug-making and industrialized drug development is the scale. In order to generate large-scale, ML-grade biodata, companies have to build wet lab infrastructures that can handle hundreds and thousands of bioassays in parallel. Depending on the modalities and models used, lab automation and device customization are needed to achieve scalability. For example, Spring Discovery built an automated experimental engine, Anvil, which integrates lab robotics, high-content imaging, and proteomics data profiling software. With Anvil, they can ‘measure hundreds of cell behaviors across thousands of conditions in every experiment’ and continuously generate data to study immune cells at scale with high fidelity.
Computing resources
Every AI-first company requires computing resources that include software, hardware, cloud storage, and various ML packages. The software can be used to execute and quality-control the automated lab workflow, digitalize bio datasets, and develop ML algorithms. Hardware stores, moves, processes and secures petabyte-scale datasets. The cloud infrastructure makes deploying ML models accessible.
Despite the similar components, ML-based platforms differ greatly between companies in complexity and how they are integrated into the drug discovery process. Some companies develop ML tools around a core function that is designated to transform a single step in drug discovery, while others stack multiple ML models to establish an end-to-end platform. Some deploy over $100M to build an in-house ‘biobank’ of disease cell models and high-content cell profiling systems to create a biological atlas for different diseases, while others leverage existing knowledge on quantum mechanics and physics and operate on low data-generation mode.
How to structure the platform is a decision that needs to take into account various factors, such as the platform-product fit, the financial situation, the company’s core competitive advantage and value, etc. Many companies adapt their strategy in structuring the platform as the company grows and pivots. There is no single, definitive ‘good platform’ that works for every company. Overall, a good platform is the one that brings the most value to the company and positions the company to shoot for its overarching goal.

Versatile business model
Industrialized platforms enable new business models. For AI-first biotech companies, when their platform can generate 10x or even 100x more drug candidates, the strategies to structure a company, build the product portfolio, and think of the value chain have changed. Here are some business models that AI-first companies often adopt.
Partnership model:
Many AI-first companies at their early stages generate income through forging partnerships with biopharma, other biotech companies, and the government. These stakeholders gain access to proprietary datasets, algorithms, or lead compounds. In return, AI-first companies will get paid in three ways: 1). Upfront payment, usually a small check made at the beginning of the partnership to cover part of the upcoming R&D. 2). Milestone payment, which is a bigger payment made when the products reach key developmental milestones. 3). Royalty payment, which is a predetermined % of revenue after products enter the market.
Incomes through partnerships are non-dilutive funding. Many AI-first companies try to secure some partnership incomes to minimize dilution from the private market fundraising. Exscientia is an example of an AI-first company that benefited from partnerships in its early development. Andrew Hopkins, the CEO of Exscientia, leveraged his connections in biopharma and built out the company’s ML platform using biobucks through partnerships with Janssen, Eli Lilly, and DSP. The first disclosed venture funding was a $17.6M Series A in 2017, 5 years after the company was founded. In addition, successful partnerships further validate the ML platforms, resulting in a snowball effect of value generation. We have seen companies get better deal terms as they developed more partnerships.
This by no means suggests that AI-first companies should maximize their partnerships. Forging a partnership means the company has to deploy resources to work with the partners, which may not align with the company’s focus. Recursion Pharmaceuticals, as a public company valued at $2B (peak value over $6B in 2021), has only two disclosed partners Bayer and Roche-Genentech. They deployed most of the resources to scale up the platform and developed an internal drug pipeline. To date, they own 5 clinical-stage programs and over 20 programs in the discovery and preclinical stages.
Internal drug discovery model:
This is a typical business model for asset-centric companies. They develop drug candidates in-house, push through the clinical trials, and bring the products to the market. Most well-funded AI-first companies also adopt this model, with the drug candidates generated or repurposed by their ML platforms. The primary reason for companies to pursue this route is the financial upside. A successful drug can bring $1B in revenue to the company each year once it enters the market. Prior to approval, clinical-stage assets can boost the company valuation as the assets pass the value inflection points. In addition, clinical-stage drug assets facilitate M&A deals with biopharma. We have seen some sizable deals on late-stage drug assets. For instance, Gilead acquired CAR-T therapy leader Kite Pharma for $11.9B in 2017. Kite’s most advanced asset axicabtagene ciloleucel was under FDA’s priority review at the time, and it became the first approved CAR-T therapy.
Even though internal drug discovery can be lucrative, the roadmap is rather risky and long. The drug candidates need to go through multiple rounds of in vitro screening and optimization in Petri dishes, validation in animal models, and three phases of clinical trials in humans to prove their safety, efficacy, and desirable drug properties. 95% of early drug candidates fail along the way. The average capital required to bring a drug candidate to the market is around $1B, which can either pay off handsomely or end with little to show for it.
ML platforms are built with the purpose to make better predictions. However, as the best medicinal chemists are not always right in picking the best leads, ML platforms still can fail. To mitigate the risk associated with the platform, many companies opt to start with established drug targets or signaling pathways that are proven to drive the diseases or repurpose existing drugs with known safety profiles. This strategy gives more buffer to the companies to explore novel pathways or new chemical space. Some companies build a pipeline that is mixed with known biology and novel targets or compounds, eg. Insilico, Exscientia.
In-house drug discovery requires access to a significant amount of capital that will be deployed to build new infrastructure, run clinical trials, and hire a completely different team of talents. To alleviate the financial risk, some companies seek partnerships or sell services to generate cash flow in the early stages.
Service-provider model:
AI-first companies may differentiate into CRO-like service providers that sell their services as products to pharma and biotech companies. For the service they provide, they charge a service fee, milestone payments, and possibly royalties from future sales of the products.
Abcellera operates as a CRO that provides antibody discovery services. They work with partners to generate data that can be fed to their antibody discovery platform, and develop the drug candidates until completion of preclinical validation before handing them off to the partners for continuing the clinical development. Abcellera has 131 contracted programs in that they have downstream participation. They structured these deals in a flexible way so that they can get returns through 1) royalties and milestone payments, 2) equities, and 3) options to invest. Currently, the majority of Abcellera’s revenue comes from royalties of two approved drugs. It is expected that once more programs enter the market, Abcellera will receive a massive financial upside. This business model allows Abcellera to maximize the efficiency of its platform and de-risk downstream development by building a large, diverse portfolio.

Spin-off model:
When an ML platform becomes efficient enough, it can generate more leads than the company wants to develop. Some AI-first companies create an umbrella LLC structure, in which the spin-off drug candidates are nested in individual subsidiaries.
Nimbus Apollo, a former subsidiary of Nimbus Therapeutics, was formed to develop several acetyl-CoA carboxylase (ACC) inhibitor programs that were generated by their ML-enabled drug design platform. Nimbus Apollo was acquired by Gilead in 2016 with a $400M upfront payment and an additional $800M in development-related milestones over time. This model allows value to be ascribed to individual products rather than the platform itself, without interrupting the platform’s development progress.
Atomwise created several joint ventures with X37 and other partners to incubate spin-off drug candidates in disease areas such as oncology and hematology while focusing on the internal development of 3 wholly-owned lead assets in immunology. This corporate structure allows Atomwise to reset the cap table and realign the development interest in certain disease areas.
It is common to see AI-first companies adopt a combination of the business models above. For example, Schrodinger, a publicly-traded company that provides software and services to drug discovery, has started developing internal drug pipelines and has recently announced its first clinical-stage asset. In response to the 2022 market downturn, some AI-first companies that are already working on developing internal drug pipelines have pivoted back to the service-provider model to reserve capital for the uncertain future. Every company needs to leverage its resources and strengths to maximize its value creation by developing internal pipelines or becoming the next Charles River in ML drug discovery service.
Scaling up like tech companies
Many biotech companies spend a decade on R&D to advance their drug programs before generating revenues from any therapeutic products because the life cycle of drugs is significantly longer than tech products. However, ML-powered biotech companies are designed to create scalable businesses. Some of the first generations of AI-native biotech companies have gone public and started revenue generation. From the disclosed data, these companies scaled up similarly to tech companies, as evidenced by the growth in platforms, pipelines, and revenues.
Platforms
AI-first companies often started on a lean model - building data and ML algorithms around a core function that they are specialized in, and scaling up as the companies raise more capital. Let’s use Recursion as an example.
Recursion was founded in 2013 by Chris Gibson, Blake Borgeson, and Dean Li as a drug discovery company that builds ML tools to analyze microscopic images of disease cells. The founders believed that a rich body of biological parameters that underlie cell fitness is hidden in their morphology. Initially, Recursion planned to use its platform for drug screening and repurposing. In parallel to building the ML platform, they in-licensed a clinical-stage compound that Chris worked on during his PhD from the University of Utah, which drove the initial success of the young company. In the following 7 years, Recursion aggregately raised $465M and built out a cell imaging-based drug discovery engine, Recursion OS, which can capture and analyze millions of disease cell images with lab automation to predict which drug compounds are the most effective to reverse the disease phenotypes. After their IPO in 2021, the platform is still growing - phenotypic readouts have been expanded from disease cell models to living animals, and SAR, ADME, and clinical prediction in being integrated into the ML workflow. To date, Recursion houses 5 clinical-stage drug programs and around 20 in the discovery/preclinical phase, and multiple programs under partnerships.

Pipeline
As a result of platform expansion, the number of ML-derived drug leads has also scaled up rapidly. By the end of 2021, there are 158 drug candidates in the discovery/preclinical stage and 15 in the clinical stage from the top 20 AI-first companies, according to this study. In comparison, the top 20 pharma companies aggregately have disclosed ~330 assets in the discovery/preclinical phase, and ~ 430 in clinical phase I. For pharma companies, drug discovery efficiency has been going down, as the cost of developing drugs increases and the number of approved drugs per capital decreases (Eroom’s Law). ML platforms have demonstrated their strengths in cutting down the costs and shortening the timeline in lead generation and optimization, and have the potential to utterly transform the economic scale and capital efficiency in drug discovery.
Soon AI-first companies will be able to generate enough leads to build a securitized drug portfolio. Andrew Lo and his colleagues proposed a financing method to fund drug development, the ‘megafund’, which pools capital from retail and institutional investors into a single financial entity on the order of $5-$30B to invest in a large portfolio of drug assets, which serves as collateral for the bonds. By increasing the diversity of the portfolios, megafunds lower aggregate risk with more shots on goal, which yield a more attractive risk-adjusted return and a higher likelihood of success. With these ideas, it is possible to see the leading AI drug discovery companies create their own megafunds with a securitized drug portfolio generated by their ML platforms. Moreover, with the help of ML models, these companies can structure their portfolios with uncorrelated drug assets to decrease the aggregate risk of the portfolio. A simulation (a little dated but still informative) showed that a hypothetical megafund for orphan diseases (very low asset correlation) can yield a 10-52% expected return with only a $575M investment and 10-20 portfolio drugs.

Revenues
Among the 40+ AI-first drug discovery companies I analyzed, Abcellera is one of the most successful companies in terms of revenue generation. Founded in 2012, Abcellera started generating steady revenue since 2018. Between 2018-2021, Abcellera’s revenue has grown from $10M to $375M. If we compare Abcellera’s revenue growth to Facebook, Twitter, and Snapchat in their early years, we can see a similar scaling pattern. The majority of revenues in Abcellera were generated from contracted antibody discovery services. The rapid growth in revenue is backed by the steadily scaling up of partnerships, just as the revenue of tech companies is correlated to the number of active users on their platforms. As of Q2 2022, Abcellera has had 38 discovery partners and 164 programs under contract.
In contrast, Recursion has been focusing on internal drug development. The two disclosed partnerships with Bayer and Roche have generated a $230M research fee. Recursion shows slower revenue growth than Abcellera, but we can expect a much bigger financial upside once their internal drug programs reach key milestones and enter the market.

Emerging trends in ML drug discovery
The field of ML-enabled drug discovery is continuously evolving. As lessons are being learned from the successes and failures of first-generation AI-native companies, new trends start to emerge. These trends are shaping the outlook of next-generation AI drug discovery companies.
A biological atlas is being created to enable mechanism-centric drug discovery
Our knowledge of disease biology only reveals the tip of the iceberg of its complexity. For this reason, it is difficult to use bottom-up models to make decisions on which protein to target or how to drug a target of interest to effectively reverse the disease phenotypes. Most drug targets are parts of complex cell signaling networks that may result in unpredictable changes (i.e. drug side effects). In addition, biological systems are highly redundant, which could blunt the effects of even the most specifically-targeted therapeutics.
New technologies (iPSCs, CRISPR, single-cell technologies, high-throughput imaging, multi-omics, etc) have improved our ability to create, manipulate, and measure the biological system at scale with granularity. Combining the most advanced ML tools, we can now create a digital atlas that represents all the molecules, pathways, and connectivity in a diseased or healthy biological system. Such a biological atlas enables mechanism-driven drug discovery and tremendously improves the accuracy of predicting drug targets or therapeutics in silico.
Some companies are creating disease maps using disease cell models or patient samples and CRISPR screens to identify novel drug targets, including Insitro, Immuai, Repare therapeutics, Tango Therapeutics, etc.
Meliora Therapeutics is building the industry’s first atlas of drug mechanisms that connect specific drug compounds to their ‘molecular fingerprints’ in cancer cells. The ‘fingerprint’, composed of multi-dimensional biomolecule profiles, is an unbiased measurement of the phenotypic effects of drug compounds. Meliora has demonstrated the power of this platform in revealing off-target effects and finding alternative drug targets with high affinities for known drug compounds. This seed-stage company just came out from stealth mode with an $11M seed round raise and is now on the track to build a full stack solution for MoA identification.
These mechanism maps are a powerful new weapon in the realm of precision medicine. By revealing previously unknown interactions and pathways, they can help highlight which proteins and pathways would be beneficial to target in drug development and give insight into whether a drug will have an impact on other pathways, which can cause side effects. Further, they provide a blueprint for identifying the right patient population with specific biomarker signatures to achieve the most effective treatment outcome.
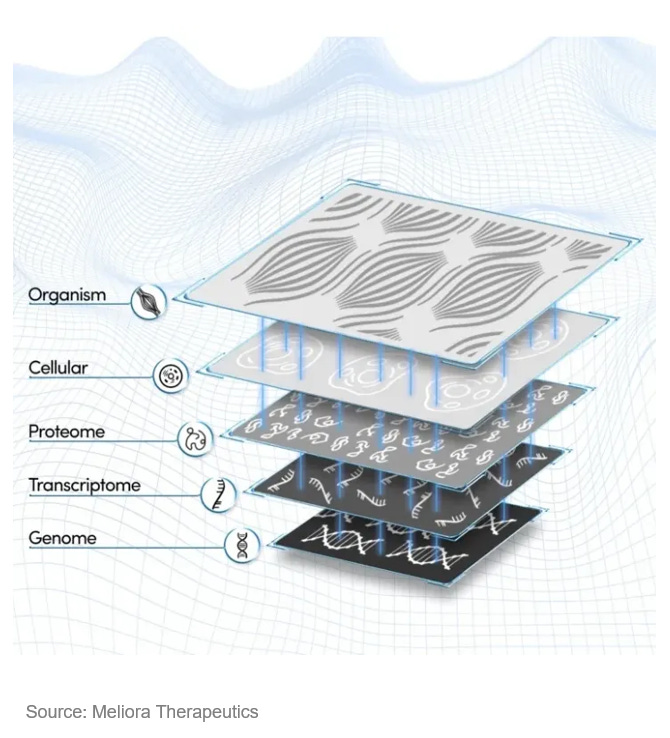
Bio frameworks gear up efficiencies in data-driven drug discovery
The future of drug discovery is data-driven. It will become a standard practice for every biotech company to engage ML tools in every step of drug discovery and development. Just as DNA synthesis, cell line production, and animal model generation have been commoditized, data will soon follow. The way how data is generated, managed, and shared in the future will look very different from today.
In the future, data generation can be outsourced to biotech CROs powered with automated robotics, high throughput systems, and cloud APIs. Scientists are able to manage the workflow and access the data through the cloud. Emerald Cloud Lab is already working in this direction.
Furthermore, SaaS companies are building cloud solutions and APIs that support biotech companies to outsource data housekeeping and analysis. LatchBio developed a cloud data infrastructure that can be latched into existing code and workflows. This solution makes it easier for bioinformaticians and data scientists to focus on their analysis workflows while having all the benefits of managed infrastructure. It also provides biologists with a set of non-coding, data analysis web tools that make data automation and ML more accessible.
In addition, some companies leverage data encryption and blockchain technologies to build platforms where proprietary bio datasets from different experimental resources can be communicated and shared safely. These companies will potentially create new business models that incentivize data sharing between different biotech companies through monetization.
As the service sector in biotech grows, these third-party companies collectively become a framework that takes care of standard, housekeeping services, which allows biotech companies to focus on developing their core competitive advantages. It has been proven in the tech world again and again that frameworks drive economic scale and efficiency. In biotech, it is just beginning.
Increasing diversity in drug modalities in ML-powered drug pipelines
Over 60% of disclosed ML-enabled drug discovery programs are developing small-molecule drugs. A key trend in biopharma has been the growth of biologics (ie. antibodies, peptides, and vaccines), due to better safety profiles, bigger therapeutic windows, and higher entry barriers for competing biosimilars relative to small molecules, which more easily lose market share to generics. BigHat Biosciences is applying ML models directly to develop more selective and less immunogenic antibody therapeutics. Abalone Bio combines ML with directed evolution to learn the relationship between antibody sequences and their control on GPCR function for better hit selection. Gene therapy is another blooming area in biotech, which has gathered $7.7B in private investment between 2019-2021. Dyno Therapeutics has carved out a niche in designing ML-assistant adenovirus-associated vectors (AAVs) to preferentially deliver therapeutic payloads to specific organs and minimize immune responses to the viral vector itself, which has been the pain point for gene therapies for years. Protein degraders are a new class of therapeutic modalities able to hijack naturally occurring biological machines, by regulating the abundance of protein targets with induced proteolysis. Celeris Therapeutics pioneers in ML-enabled proximity-inducing compound design focused on targeted protein degradation. In addition, Finch Therapeutics and Persephone Biosciences both use ML technologies to develop microbial therapeutics for patients with serious and unmet medical needs.
The continuous evolution of ML technologies
Just as AI face recognition wasn’t reliable until the convolutional neural network was employed to train the AI how to interpret images and extract face information. The performance of ML in drug discovery is limited by our ability to design ML algorithms to accurately represent nature. If we can more realistically describe the fundamental nature of the protein-ligand binding, we will likely be able to better predict the phenomenon. Genesis Therapeutics is working to create a richer, more complex molecule descriptor using deep neural networks, which represent molecules as graphs. With this descriptor, they can capture more complicated, 3D-shifting conformations of atoms and bonds in a molecule. This platform is supposed to help to ‘unlock novel protein targets and explore unknown chemical space’. Aquemia is developing a quantum mechanics-based affinity predictor with 10x higher efficiency and accuracy, which is used to generate new compounds in silico directly from the target structure without large-scale experimental data.
ML technologies have made a splash in drug discovery, yet it is still in their infancy. In a few years, we will have a better understanding of the performance of ML-designed drugs and will know better how to value ML platforms and adapt the technologies. It is important to set realistic expectations of what can do, as ML is not magic that can solve all problems. Even if it can increase the success rate of an early-stage compound from 5% to 10%, there is still a 90% chance to fail. Nevertheless, the time of ML-powered data-driven drug discovery has come.
Acknowledgement: Big thanks to my friends David Li and Vandon Duong for their valuable time and constructive feedback on this post.
Lin Ning, the framework (including X/Y axis titles and placement for companies) you have included comes from Recursion's IPO brochure with few additional companies added on top. Please reference.